Democratizing data access through natural language and intelligent interfaces
Challenge
While GitLab offers powerful data query capabilities through GLQL (GitLab Query Language), non-technical users struggled to answer their own data questions. Business analysts, product managers, and other data consumers relied on engineering support to write queries, creating bottlenecks and limiting data-driven decision making across the organization.
My role
I lead the design effort, closedly collaborated with with cross-functional teams on problem and solution validation.
Approach
Understanding the barriers to data access
Currently in the process of conducting research with different personas to understand how they currently accessed and analyzed data:
- Data engineers
- Business analysts
- Product managers
- CS teams
Mapping user journeys across skill levels
Working on mapping out end-to-end journeys for each persona, identifying where friction is occurring and what capabilities would be most impactful. This helped prioritize which features should launch first and how they should connect.
The solution needs to:
- Lower the barrier to entry for non-technical users
- Maintain power and flexibility for technical users
- Bridge the gap between natural language questions and structured data queries

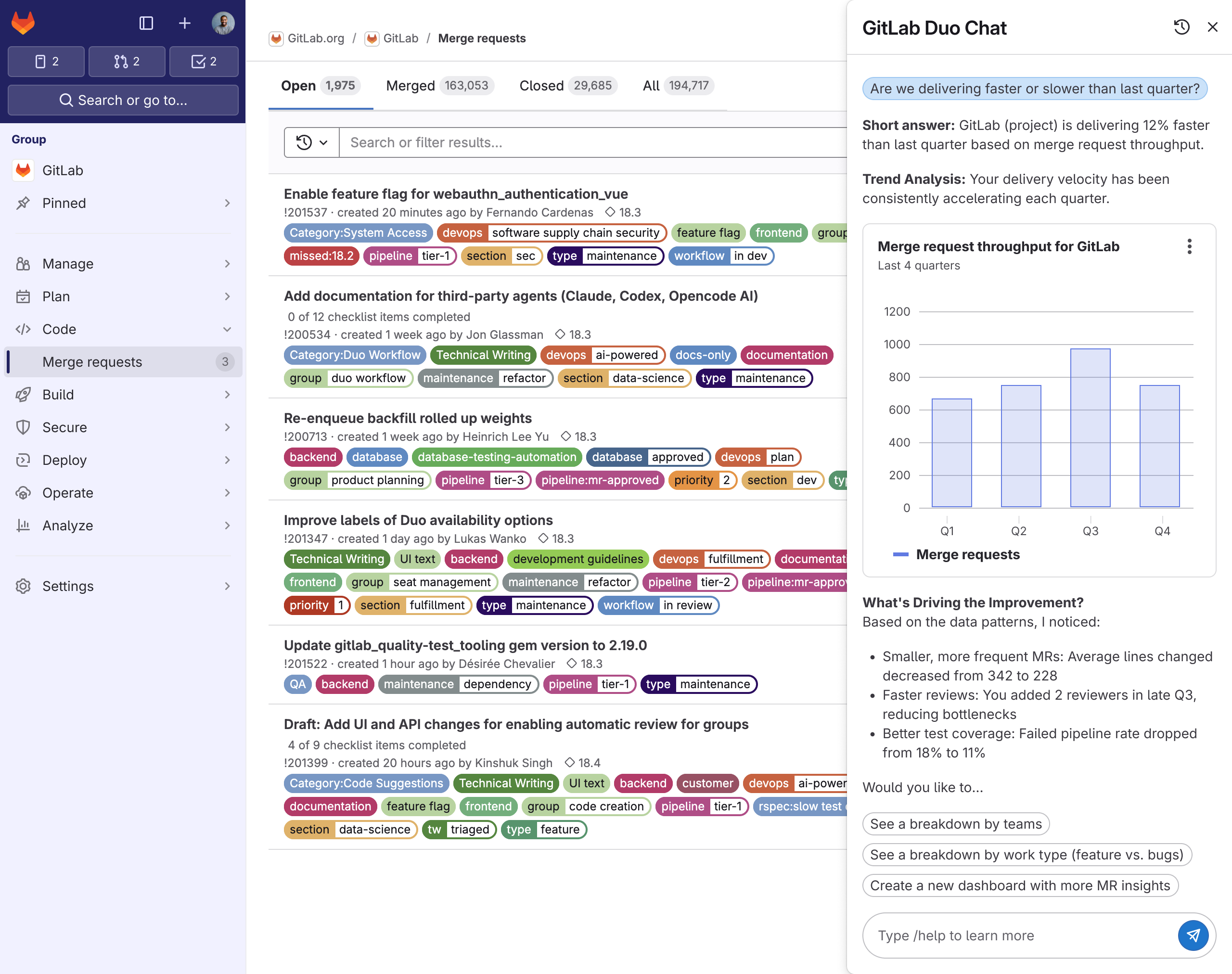
Data exploration using Duo chat
Designing the AI-powered experience
I explored multiple approaches to natural language data exploration:
- Conversational interfaces where users could ask questions in plain English
- Guided query builders that suggested relevant metrics and filters
- Hybrid approaches that translated natural language to GLQL, allowing users to learn over time
- Princilpals for designing for non-deterministic systems
Collaborating on technical architecture
I am working closely with the Data Science and AI Engineering to understand the capabilities and limitations of natural language processing for our use case. This collaboration is helping to define:
- What types of queries the system could reliably interpret
- How to handle ambiguity and provide helpful suggestions
- How to surface confidence levels and allow users to refine results
Solution
An AI-powered data discovery experience that:
- Accepts natural language queries: Users ask questions in plain English (e.g., “Show me merge request cycle time for teams using AI”)
- Translates to structured queries: The system converts natural language to GLQL, making the logic visible and editable
- Provides intelligent suggestions: Offers relevant metrics, filters, and time ranges based on context
- Enables progressive learning: Shows the underlying query structure so users can learn GLQL over time
- Surfaces confidence indicators: Helps users understand when results might need refinement

Data exploration using Duo chat
Desired outcomes
- Reduce dependency on engineering: Non-technical users should answer their own data questions without support
- Increased data-driven decision making: More teams across GitLab leverage data in their daily work
- Improved data literacy: Exposing the underlying query logic will help users learn and grow their skills
- Validate AI use case: Demonstrated clear value for AI-enhanced experiences in enterprise tools
- Inform future strategy: Insights from this work will shape the next generation of data discovery at GitLab
Key Learnings
Successful AI-powered features balance automation with transparency. Users need to understand what the system was doing and have the ability to refine results. The most effective approach isn’t to hide the technical complexity entirely, but to progressively reveal it.
This work will also reinforced the importance of designing for diverse skill levels within a single experience. Rather than creating separate tools for technical and non-technical users, we created flexible interfaces that adapted to each user’s needs.