Turning natural-language questions into trustworthy answers
Challenge
GitLab holds a vast amount of system and engineering data, queryable through GLQL (GitLab Query Language). But asking a question meant knowing the query language, which put a translation layer, usually a person, between someone with a question and the answer. Engineers debugging a regression, analysts checking a trend, managers assessing team health: all blocked on the same bottleneck, all slowed at exactly the moment speed matters. When the cost of asking is high, people ask fewer questions and make decisions on weaker evidence.
My role
I lead the design effort and collaborate closely with cross-functional partners on problem and solution validation.
Approach
Understanding who’s blocked, and how badly
I ran research across data engineers, business analysts, product managers, and support teams to map how each currently gets to an answer and where the friction is. The personas differ in skill but share a structure: a question, a translation tax, a delay, a decision made with whatever evidence was cheap enough to get.
The principle: lower the floor without lowering the ceiling
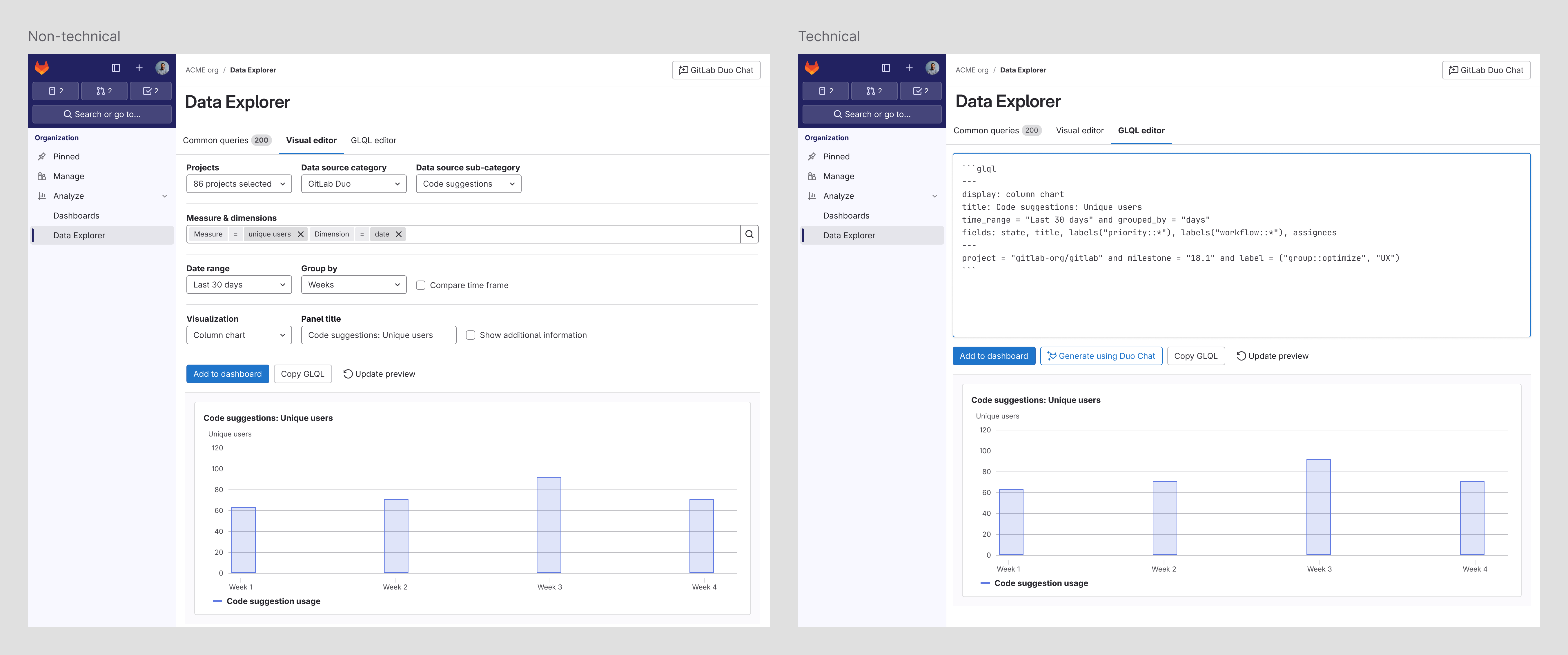
The solution has to:
- Let someone ask in plain language and get to a trustworthy answer fast
- Preserve full power and precision for technical users who already think in queries
- Make the gap between a natural-language question and a structured query visible and learnable, not hidden
Designing for non-deterministic systems
The core craft problem isn’t the happy path, it’s what happens when the system is unsure or wrong. I explored conversational entry, guided query building, and a hybrid that translates natural language into editable GLQL, and established principles for surfacing confidence, handling ambiguity, and letting users correct the system instead of starting over. A confident wrong answer is worse than a slow right one; the design has to make uncertainty legible.
Collaborating on what’s actually feasible
I work with Data Science and AI Engineering to ground the design in what natural-language interpretation can and can’t do reliably for our data, which questions translate cleanly, where ambiguity needs a human-in-the-loop, and how to expose confidence so users calibrate their trust correctly.
Solution
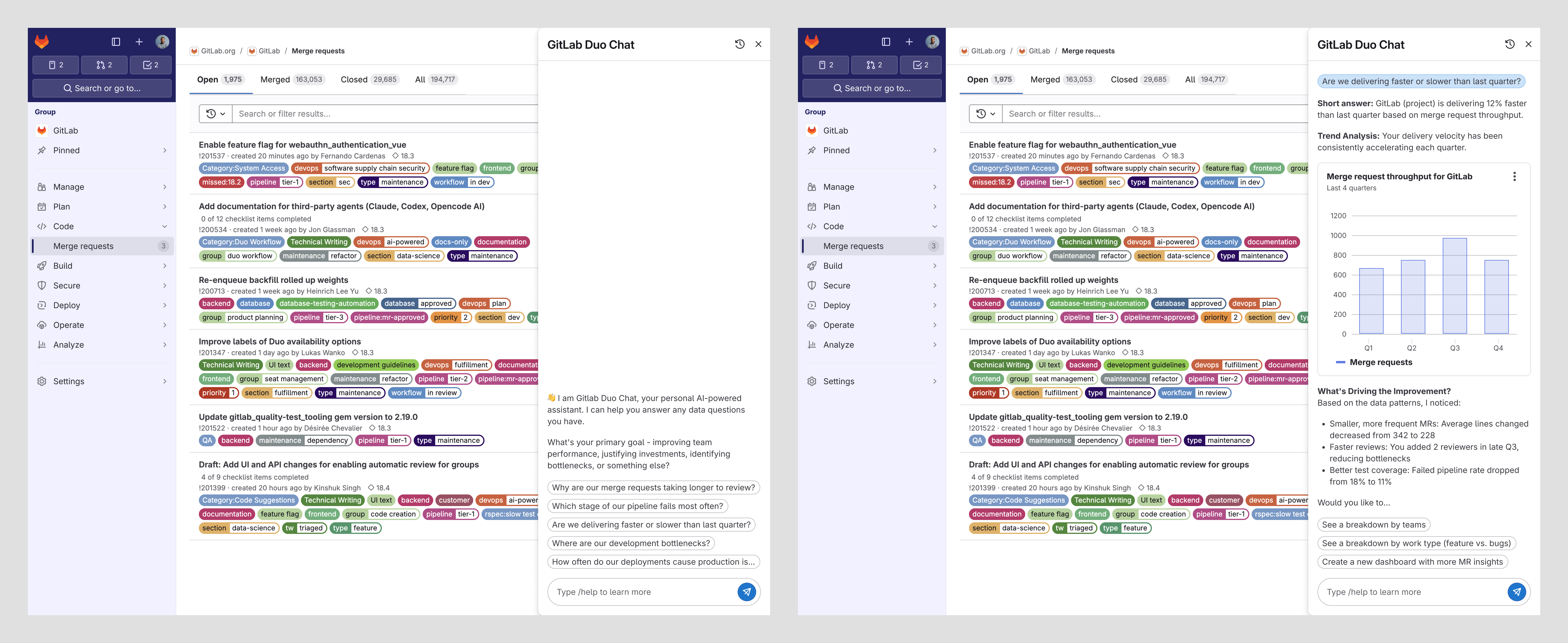
An AI-assisted discovery experience that:
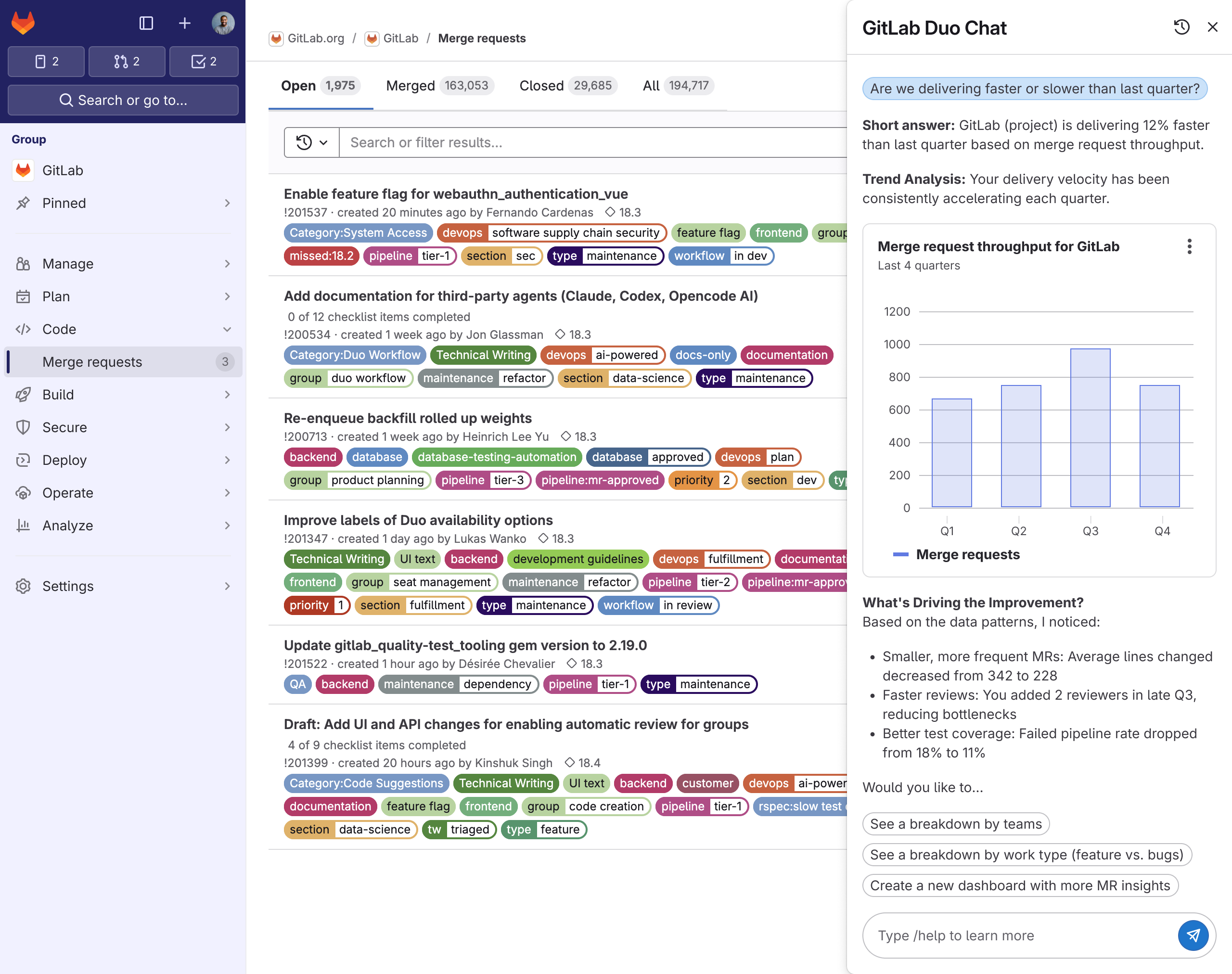
- Accepts plain-language questions (e.g., “show merge-request cycle time for teams that adopted AI review” — or, for an engineer, “which services’ error rate changed after the last deploy”)
- Translates to structured, visible, editable GLQL, so the logic is inspectable rather than a black box
- Suggests relevant metrics, filters, and ranges from context
- Reveals the query progressively, so users learn the language over time instead of staying dependent
- Surfaces confidence, so people know when an answer needs a second look
Why this matters beyond analytics
The thing being designed here is not “an analytics feature.” It’s a system for getting a trustworthy answer out of a large, queryable body of system data, fast, for someone who shouldn’t have to be an expert in the query layer — while keeping the expert’s power intact and making the machine’s uncertainty visible. That is structurally the same problem as AI-assisted troubleshooting and guided root-cause analysis in an observability context: different data (traces, metrics, logs instead of engineering metrics), identical design problem (natural-language intent → structured query → a result an engineer can trust under pressure, with the reasoning inspectable and the confidence legible). The principles I’m establishing here for non-deterministic, confidence-aware, progressively-disclosed querying transfer directly.
Desired outcomes
- Reduce dependency on engineering: Non-technical users should answer their own data questions without support
- Increased data-driven decision making: More teams across GitLab leverage data in their daily work
- Improved data literacy: Exposing the underlying query logic will help users learn and grow their skills
- Validate AI use case: Demonstrated clear value for AI-enhanced experiences in enterprise tools
- Inform future strategy: Insights from this work will shape the next generation of data discovery at GitLab
Key learnings
Trustworthy AI features balance automation with transparency: people need to see what the system did and be able to correct it. The most effective approach isn’t hiding technical complexity, it’s revealing it progressively, so the tool meets a novice where they are and a power user where they are, in one experience, without a confident-wrong answer ever going unflagged.