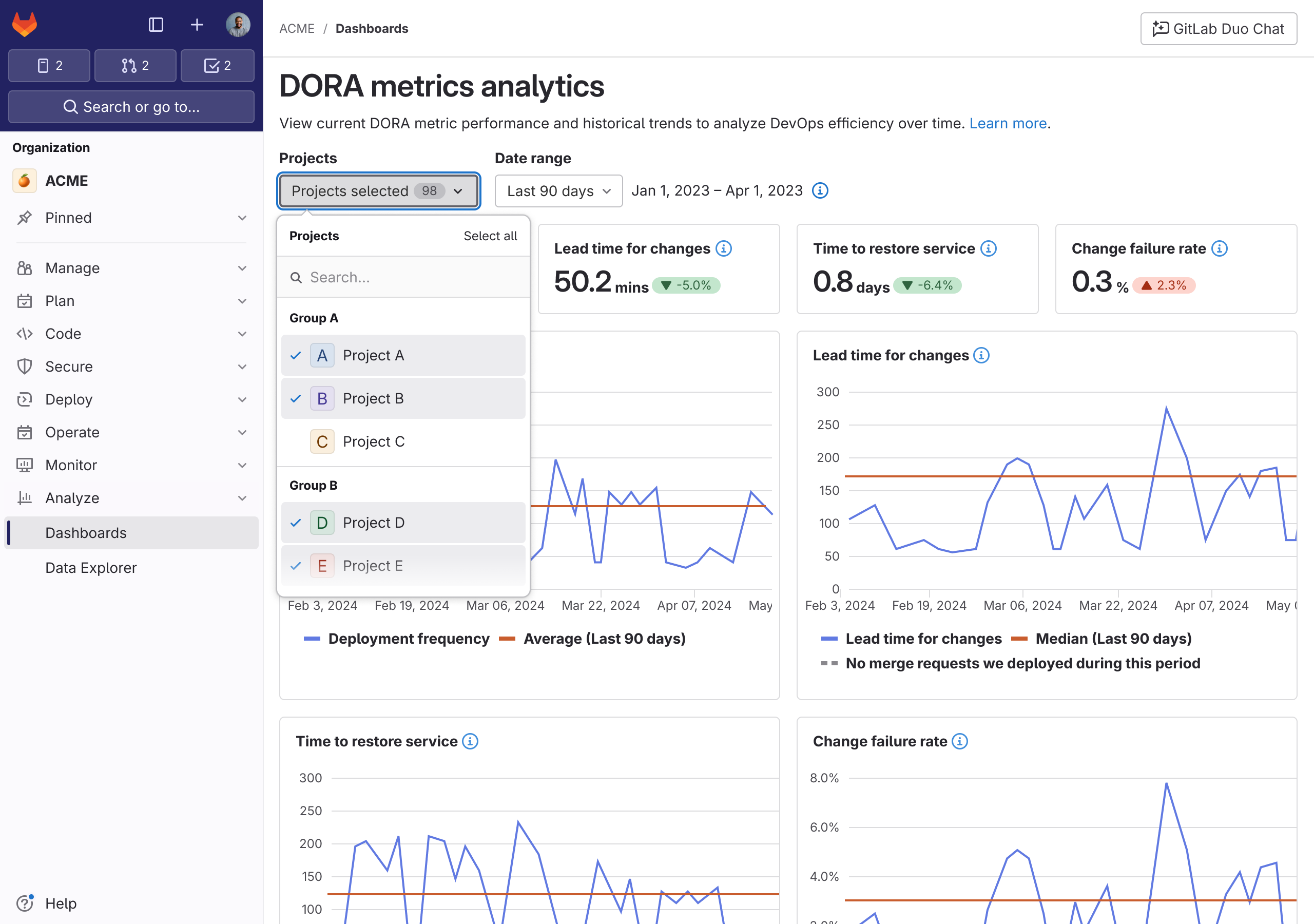
Challenge
GitLab’s data access was tied to its nested group structure rather than to user permissions. The consequence: customers couldn’t roll up metrics across teams they managed unless those teams shared a parent group in the application hierarchy — which, for any organization that didn’t accidentally mirror its data needs in its repo structure, meant most cross-team analysis was simply unavailable. The static dashboards that did exist suffered low adoption for related reasons: users couldn’t aggregate across organizational boundaries or build views for their own questions. A model that should have empowered cross-team decisions was actively preventing them.
My role
- Led the design effort to rethink the data access model end-to-end
- Joined customer calls with my PM to understand how the constraint surfaced in real workflows
- Partnered with engineering on what extensions to GLQL (GitLab’s query language) would be needed to support cross-group aggregation and visualization rendering
- Collaborated with designers across product areas affected by the change
Approach
Naming the systemic constraint
I worked with Product and Engineering to map the existing system explicitly: data access was bound to application structure (nested groups), and every downstream limitation followed from that single coupling. Until that coupling was named as the problem, every team was solving symptoms.
Designing the separation
I designed a model that decoupled data access from application structure entirely — moving access to a permission basis at the organization level, so the question “what can this user see?” stopped being a function of “where in the group tree does the data sit?” That unlocked permission-based access, self-service dashboard creation and sharing, and flexible aggregation across whatever organizational shape a customer actually had.
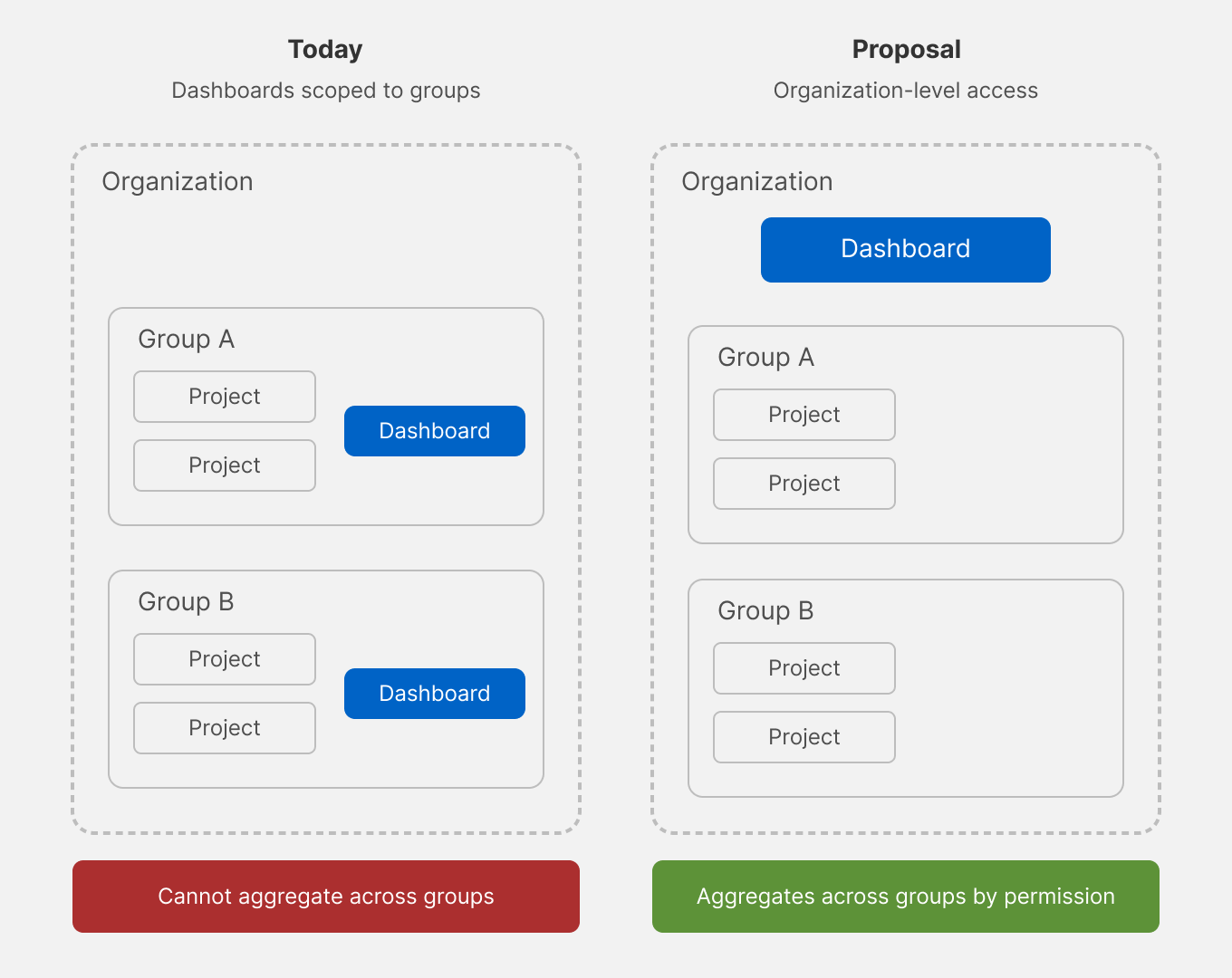
Engineering partnership on what was possible
I partnered with engineering to understand the constraints of GLQL and what extensions it would need to support both cross-group queries and visualization rendering. Decoupling the access model was the design move; making GLQL able to support it was the engineering one, and the two had to be designed together.
Building on shared foundations
The dashboard surfaces this work shipped through were built on the data-visualization patterns and components from a parallel initiative — see Data Visualization Design System. Reusing those foundations meant the access-model rethink could be evaluated on its own merits without each team rebuilding the dashboard UI from scratch.
Solution
A redesigned data access model that delivered:
- Permission-based data access at the organization level, decoupled from group hierarchy
- Self-service dashboard creation, customization, and sharing for users with the right permissions
- Flexible aggregation across GitLab’s group structure, so customers could roll up metrics along the organizational shape that actually mattered to them
- Extended GLQL to support data visualization rendering and cross-group queries
Outcomes
- Customers could roll up metrics across teams they managed, removing a long-standing class of ‘can’t get there from here’ requests
- Self-service replaced engineering-mediated dashboard creation, reducing the bottleneck and the request load
- Diverse workflows were supported by a single flexible model rather than per-team workarounds
- Internal teams started consolidating onto these dashboards instead of using third-party BI tools, reducing cost and increasing data trust
Key insight
Most “we need a better dashboard” requests are actually access-model requests in disguise. The visible surface is the dashboard; the constraint is upstream, in how data is exposed and aggregated. Designing the access model — the part the user never sees but that determines what any dashboard can ever show them — is sometimes the highest-leverage interaction design problem on the project.